Synthetic data generation
Why label a dataset if you could
synthesize it?
Learn how Supervisely can dramatically improve model training results or even make impossible — possible!
Trusted by Fortune 500. Used by 80,000+ companies and researchers worldwide




















What's a synthetic data generation?
Get bottomless training data with little to no labeling
A traditional approach to model training has many steps, but it always includes the most challenging part: data annotation. There are many potential issues:
Standard workflow:
Weeks to months- 😥Extremely time and money consuming
- 😥Error-prone, people can make mistakes
- 😥New scenarios and conditions means more labeling
Fortunately, there is a better way. Instead of labeling dataset, we can programmatically compose it from different parts. For example, we are building an OCR system for shop receipts. Rather than labeling photos of read-world receipts, we can generate infinite amount of synthetic receipts that look almost identical. Since we generate all the labels, we don't need the labeling and can proceed straight to the model building.
Almost identical? This may seem like a problem at first, but many researches show that it's impossible to perfectly simulate real world — instead, it's better to teach model to adapt and learn from randomization.
Alternative workflow:
Minutes to hours- 😃Much less human involvement, immediate output
- 😃In case of issues, just re-generate the whole dataset
- 😃Easy to adapt to any changes
Synthetic data generation approach doesn't applicable for every task. But, usually, when it works, it works very well. What about you case? Get in touch with us and we will figure it out!
How does it work?
Here is an example of generating a synthetic dataset for instance segmentation of seeds. Exactly the same pipeline works for many other tasks, such as microbes or pathology detection.
Basic primitives
Label subset of you data or obtain it from external sources
+

Backgrounds
Usually, it's easy to find or generate typical backgrounds
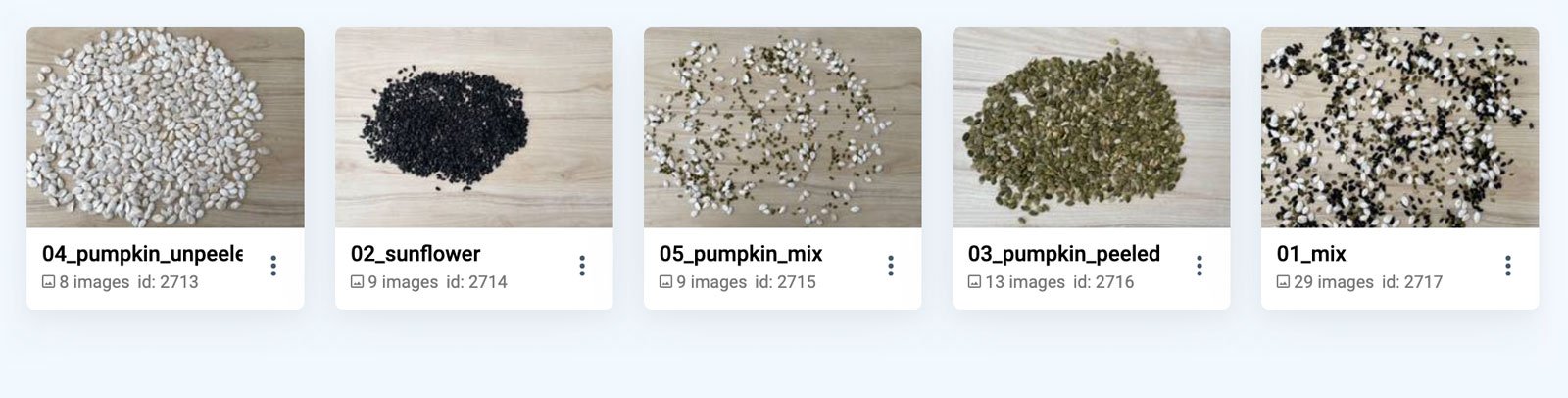
Input dataset
Just under 70 images is enough to represent every case we want to cover
Run Supervisely App
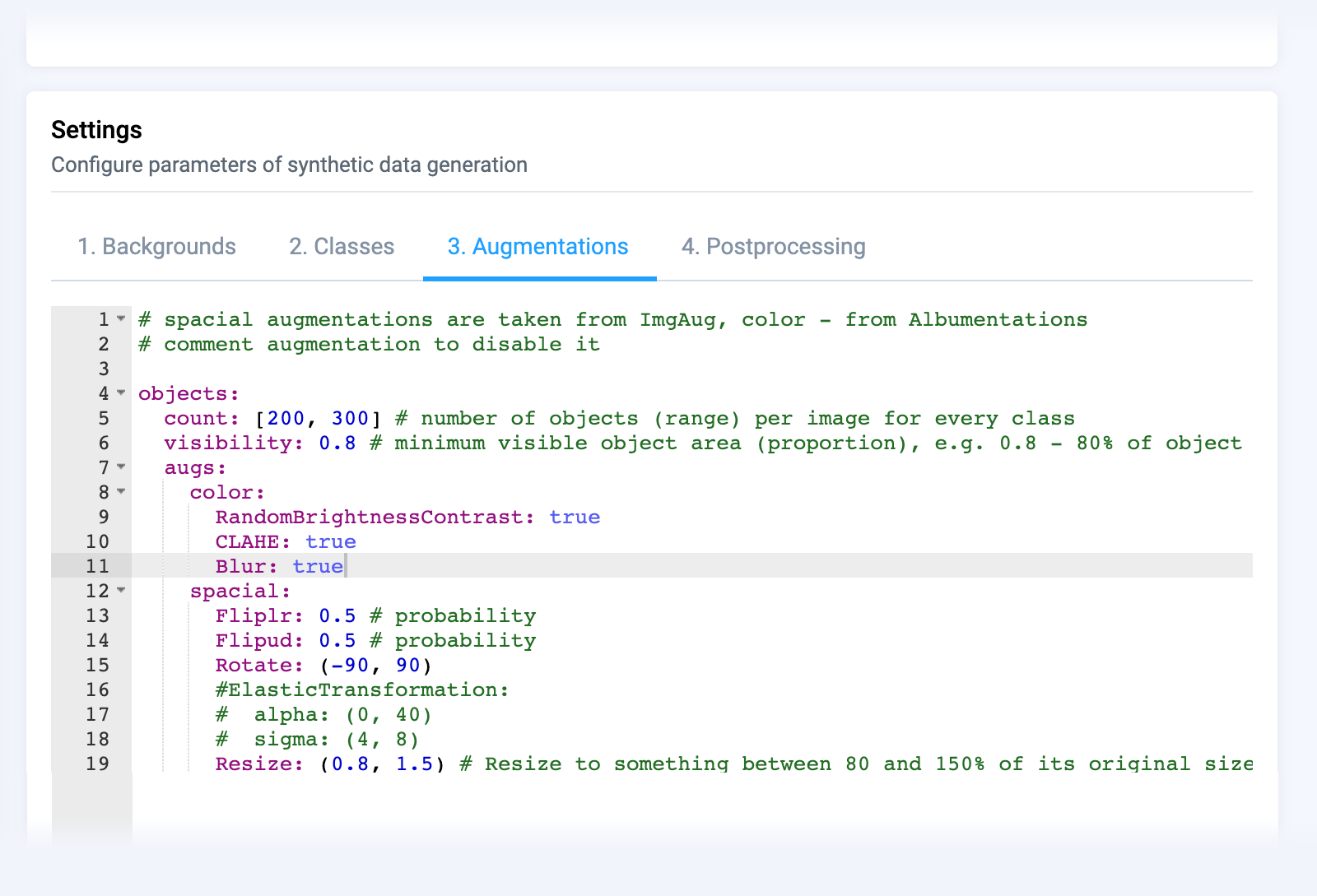
Let's apply synthetic generation application from the Ecosystem with an appropriate configuration

Generate synthetic data: flying foregrounds on top of backgrounds
Get labeled dataset
Done! Verify generated data and start model training
Watch Flying Objects in action

For every step in AI pipeline
From Zero to Hero and beyond
Because Supervisely is built like OS for computer vision, we made possible integration of the best machine learning models and tools on a single platform.
You will find a well-known projects from data science community, as well as our own Apps, providing a complete solution for entire AI development pipeline.
Train state-of-the-art models in browser
Configure every aspect of training from target classes to online augmentations, monitor metrics and terminal logs in real-time.

Dashboard to configure and monitor training
Visualize, analyze and improve performance
Understand how your model works on ground truth and new data and find how to correct negative output and increase performance.
Detailed statistics for all classes in images project

Boost training with synthetic data
Generate synthetic datasets that drastically improve model results, especially when there is not enough ground truth.
Generate synthetic data: flying foregrounds on top of backgrounds
Query and transform, run augmentations
Perform all the necessary actions on your data, from importing and converting to skeletonization of masks and rasterization.

Configure, preview and split images and annotations with sliding window
SUPERVISELY FOR ENTERPRISES
On-premise edition built for your business
A fully customizable AI infrastructure, deployed on cloud or your servers with everything you love about Supervisely, plus advanced security, control, and support.
Start 30 days free trial➔- Maximum security: hosted behind firewall on your servers with advanced governance and privacy settings
- Effortless integrations: single sign-on with LDAP or OpenID, cloud storage in AWS or Azure and powerful API & SDK
- Priority support: dedicated slack chat, guided onboarding and personalized training sessions with experts
> downloading pre-requirements...
> pulling docker images...
> installing software...
> Done! Supervisely is running on port :80
supervisely update
> checking for updates...
> Your version is up to date!





Here’s why our customers trust us


We use Supervisely since 2019. The key advantage of this tool is that Supervisely provides a complete data treatment pipeline. An important advantage is that a Supervisely instance can be deployed autonomously on a Client infrastructure, and distributed on different servers.
It helps to treat enterprise’s internal and often confidential data in a secured way. Together with a user-friendly interface, a clear documentation and a friendly and reactive support team it helps us to do Data Scientist work better and faster.

BMW Group is using the Supervise.ly solution to create automated verifications for ensuring a very high product quality across the whole production chain in vehicle and vehicle component manufacturing.
BMW Group uses Supervise.ly to annotate manufacturing images from production lines in their world-wide plants for enhancing quality inspections using deep learning. The Supervise.ly tooling also supports the process for continuously updating AI models using semi-automated labeling.
Supervise.ly is integrated into the BMW Group AI Platform in order to empower computer vision based AI use cases.

We originally set out to look for tools that could help us with data annotation, and we discovered that Supervisely excels at that and much more. It has become an integral part of our workflow in annotation, model training, and evaluation.
We've been exceedingly impressed with the customer support, addition of new features, and the flexibility of the publicly available SDK/API. The Supervisely team has also been fast to respond to support questions, and has shown a lot of openness when given feedback on potential improvements.


We have been using Supervisely for a few years now to help label and organize our data for AI training. The interface is user-friendly and the tools are intuitive to use, which has made the annotation process much more efficient for our team. We run Supervisely locally, which allows us to stay in control of our data. We also use Supervisely for annotation reviews, and the review tools have been invaluable in ensuring the quality and accuracy. The Python SDK has also been incredibly helpful in automating and streamlining our workflow. In addition, the support team on Slack has been extremely helpful and responsive. The ability to collaborate with my colleagues on the same project has also been a huge time-saver.
Overall, we have been extremely satisfied with Supervisely and would highly recommend it to anyone in need of a reliable and efficient annotation solution.
7
years
Supervisely provides first-rate experience since 2017, longer than most of computer vision platforms over there.
80,000+
users
Join community of thousands computer vision enthusiasts and companies of every size that use Supervisely every day.
1,000,000,000+
labels
Our online version has over a 220 million of images and over a billion of labels created by our great community.
Trusted by Fortune 500. Used by 80,000+ companies and researchers worldwide
Contact Us
Ready to get started?
Speak with people who are on the same page with you. An actual data scientist will:
- Show live demo
- Go through the concepts
- Learn your case
- Offer a tailored solution
Get you data labeled
Get accurate training data on scale with expert annotators, ML-assisted tools, dedicated project manager and the leading labeling platform.
Order workforce


